Getting Started
KodiBot - A Local Chatbot App for Desktop
KodiBot is a desktop app that enables users to run their own AI chat assistants locally and offline on Windows, Mac, and Linux operating systems. KodiBot is a standalone app and does not require an internet connection or additional dependencies to run local chat assistants. It supports both Llama.cpp compatible models and OpenAI API.
KodiBot is free and open source app developed using electronjs framework and released under the GNU General Public License.
Requirements
- Average gaming PC or laptop with Windows, Mac, or Linux operating system
Features
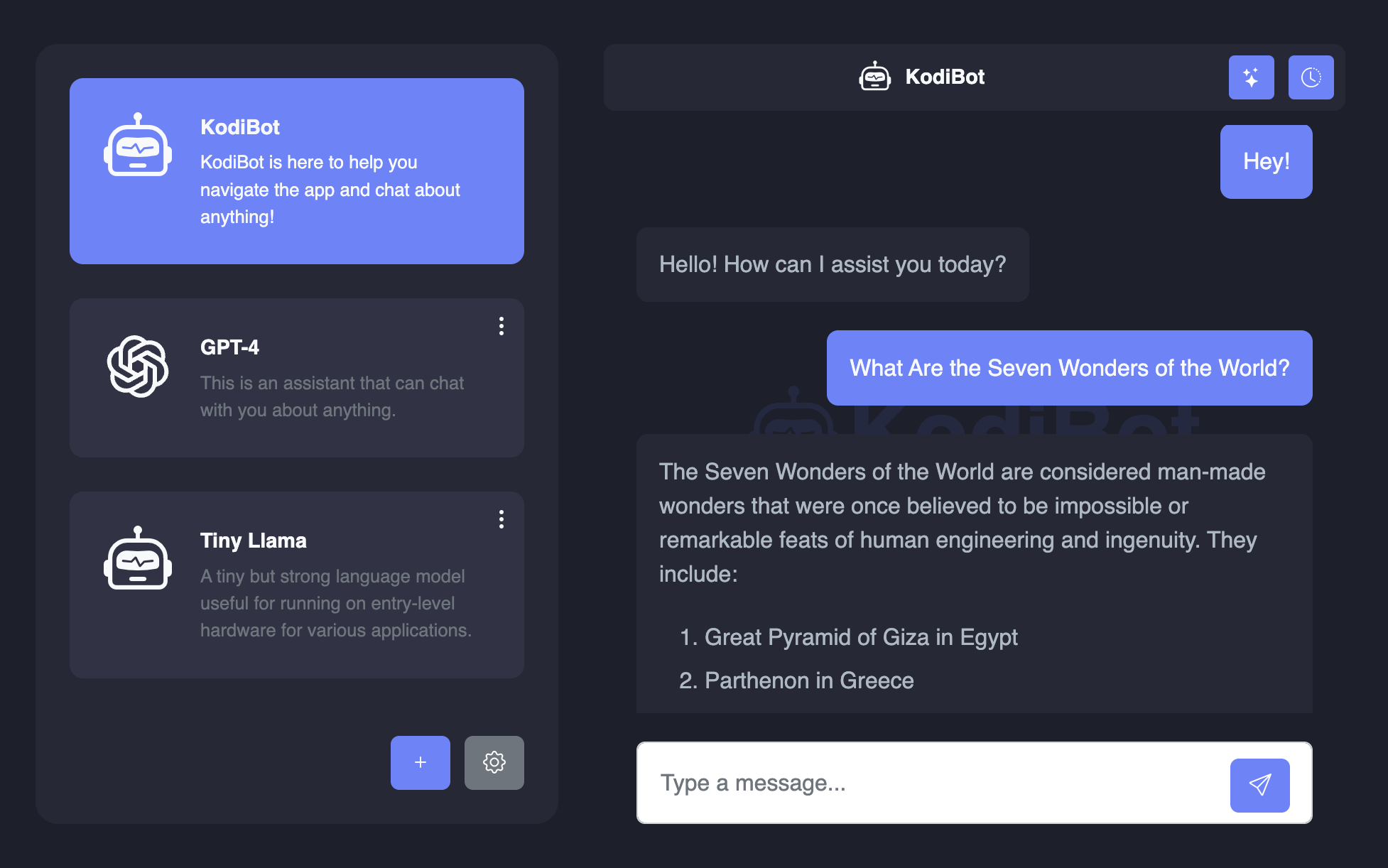
KodiBot has a simple and user friendly interface. Same as any chat app, you can start chatting with your assistant by selecting an assistant from the list.
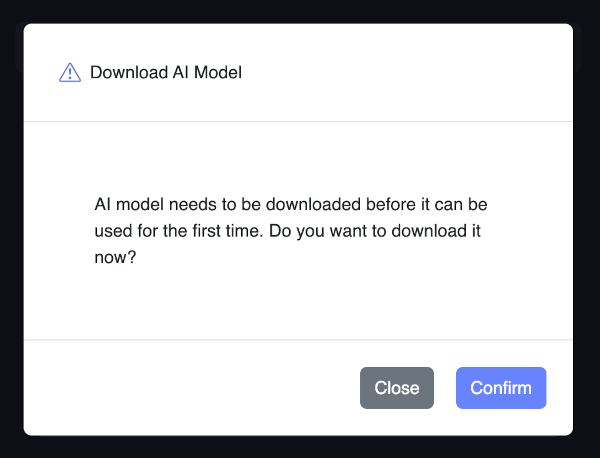
When you first start the app, you'll be prompted to download the model file for the kodibot assistant. Once the model is downloaded, you can start chatting with your assistant right away.
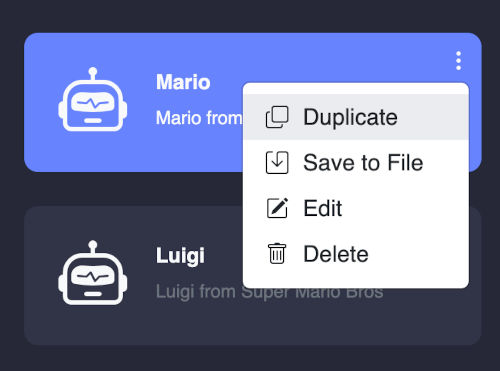
You can access assistant card settings from top right corner of each assistant card. You can customize the assistant settings such as name, model file, prompt, history template, API URL, and port. You can also delete the assistant card from the settings.
- Duplicate: Duplicate the assistant card
- Save to File: Save the assistant card setting to JSON file
- Edit: Edit the assistant card settings
- Delete: Delete the assistant card
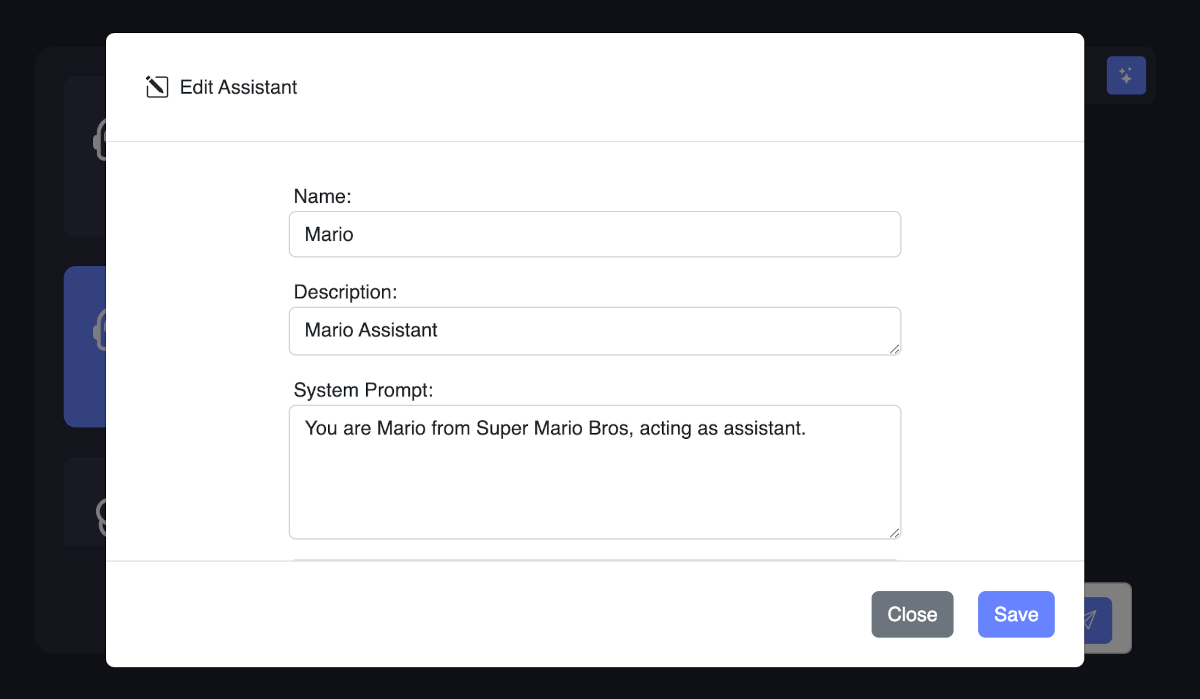
You can esily create chat assistant cards and customize them for specific tasks or topics by adding instructions. You can save cards to JSON file share them with others.
KodiBot stores your history with each chat assistant separately. You can easily navigate and switch between chat assistants from the sidebar.
Creating Local Assistant
You can either duplicate an existing KodiBot assistant card or create a new one.
Easy: Duplicating Existing Assistant
Duplicating an existing assistant card is the easiest way to create a new assistant. You can simply customize the instructions for your specific task or topic and start chatting with your assistant.
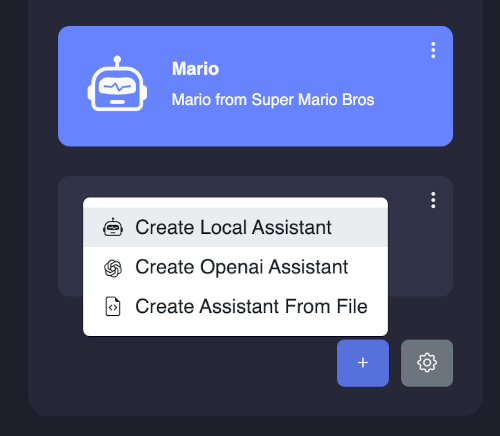
Advanced: Creating New Assistant
If you create a new local assistant, you can choose the default model file or you can add your own model from the "+" button. KodiBot supports custom models that are compatible with Llama.cpp. You can download models from huggingface.co or other sources.
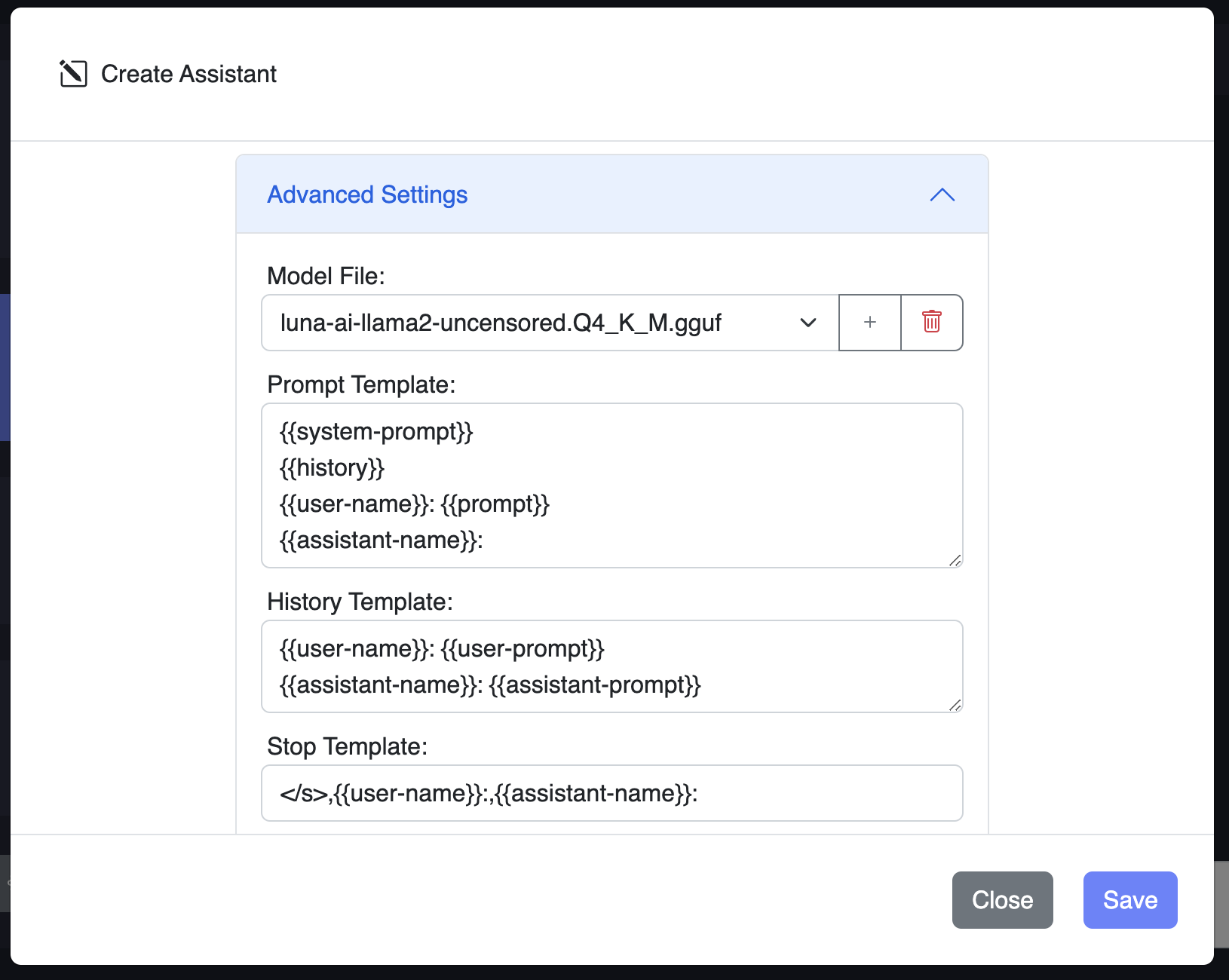
You'll also need to add prompt and history template to be able to feed proper prompt to the model you choose. You can find these information in the model's documentation. You can leave other advanced settings as default. Template keywords for system propt and history are as follows:
{{system_prompt}}: System prompt{{history}}: Chat history block from the history template{{user_name}}: User name{{user_prompt}}: User prompt{{assistant_name}}: Assistant name{{assistant_prompt}}: Assistant prompt
You can either use the default parameters or fine tune them for your needs.
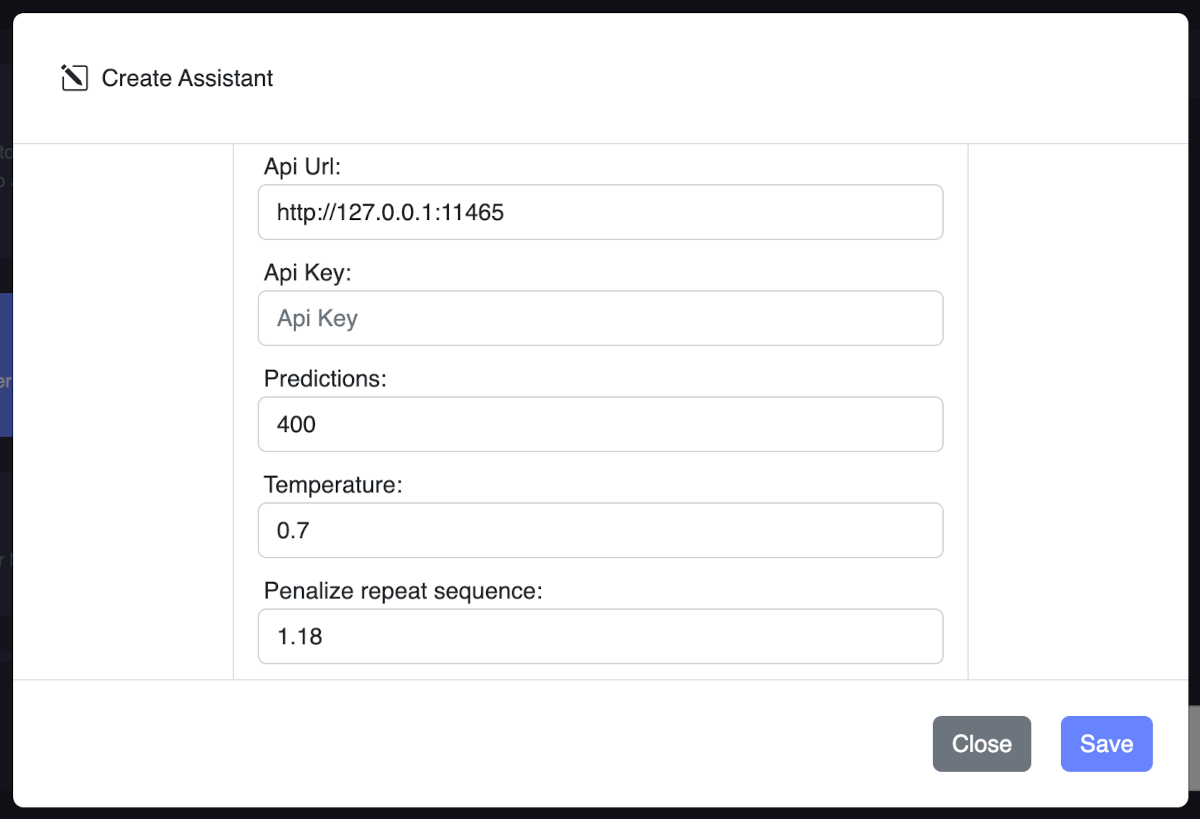
- Api url: The API URL is the endpoint where the AI model is hosted. It is used to send user inputs to the AI model and receive responses.
- Api key: The API key is a unique identifier used to authenticate requests to the AI model. It is used to ensure that only authorized users can access the AI model.
- Predictions: Maximum number of tokens to predict when generating text. May exceed the set limit slightly if the last token is a partial multibyte character. When 0, no tokens will be generated but the prompt is evaluated into the cache. Default: -1, where -1 is infinity. - - -
- Temperature: Adjust the randomness of the generated text. Lowering results in less random completions.
- Penalize repeat sequence (Repeat penalty): Helps prevent the model from generating repetitive or monotonous text. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. The default value is 1.1.
- Consider N tokens for penalize (Repeat last n): Controls the number of tokens in the history to consider for penalizing repetition. A larger value will look further back in the generated text to prevent repetitions, while a smaller value will only consider recent tokens. A value of 0 disables the penalty, and a value of -1 sets the number of tokens considered equal to the context size.
- Top-K sampling: Helps reduce the risk of generating low-probability or nonsensical tokens, but it may also limit the diversity of the output. A higher value for top-k (e.g., 100) will consider more tokens and lead to more diverse text, while a lower value (e.g., 10) will focus on the most probable tokens and generate more conservative text.
- Top-P sampling: This method provides a balance between diversity and quality by considering both the probabilities of tokens and the number of tokens to sample from. A higher value for top-p (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text.
- Min-P sampling: The Min-P sampling method was designed as an alternative to Top-P, and aims to ensure a balance of quality and variety. For example, with p=0.05 and the most likely token having a probability of 0.9, logits with a value less than 0.045 are filtered out.
- TFS-Z: Tail free sampling (TFS) is a text generation technique that aims to reduce the impact of less likely tokens, which may be less relevant, less coherent, or nonsensical, on the output. Typical values for z are in the range of 0.9 to 0.95. A value of 1.0 would include all tokens, and thus disables the effect of TFS.
- Typical P: Locally typical sampling promotes the generation of contextually coherent and diverse text by sampling tokens that are typical or expected based on the surrounding context. A value closer to 1 will promote more contextually coherent tokens, while a value closer to 0 will promote more diverse tokens.
- Presence penalty: How much to penalize new tokens based on whether they appear in the text so far. Increases the model's likelihood to talk about new topics. Each assistant card can be deleted or duplicated from top left dropdown menu buttons.
- Frequency Penalty: How much to penalize new tokens based on their existing frequency in the text so far. Decreases the model's likelihood to repeat the same line verbatim.
- Mirostat: Enable Mirostat sampling, controlling perplexity during text generation. Default: 0, where 0 is disabled, 1 is Mirostat, and 2 is Mirostat 2.0.
- Mirostat tau: Set the Mirostat target entropy, parameter tau.
- Mirostat eta: Set the Mirostat learning rate, parameter eta.
Using OpenAI API
With OpenAi API you can use latest Chat GPT models without paying monthly subscription fees, you only pay for what you use with a pay-as-you-go pricing. You can use OpenAI API by creating an API key from OpenAI. Then you can add your API key to assistant settings.
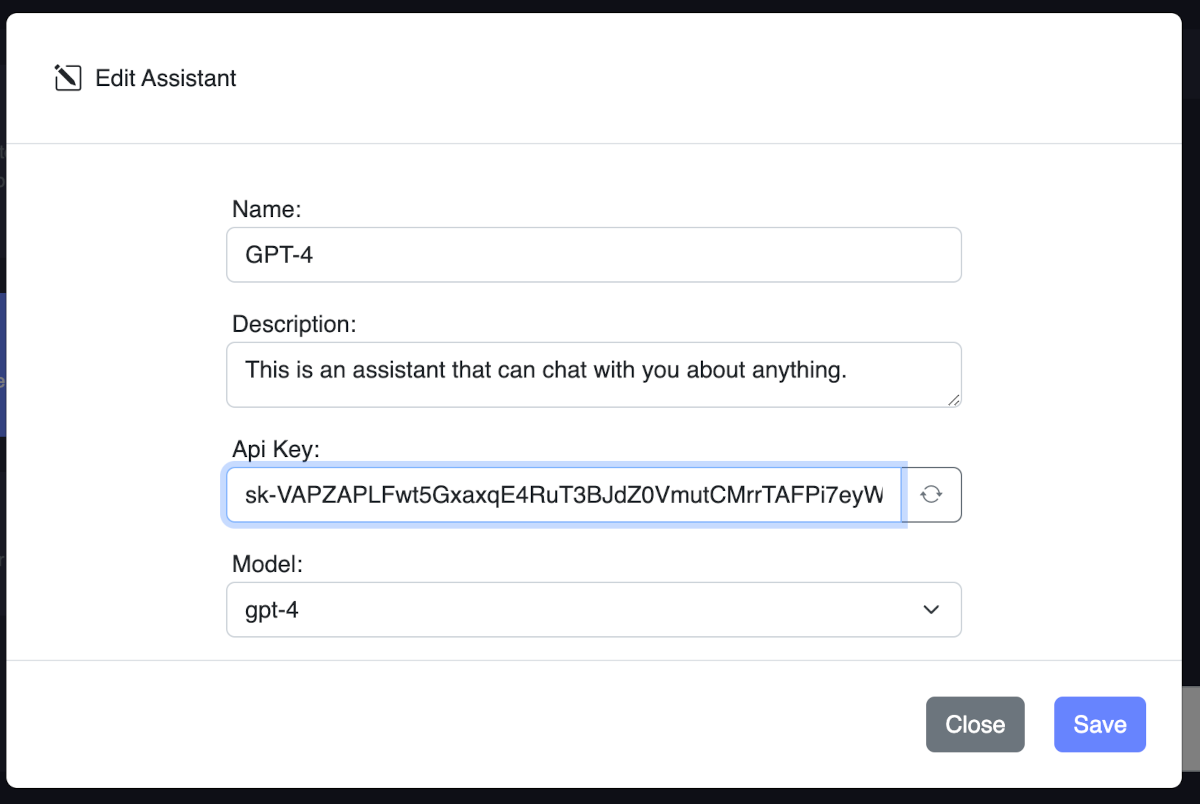
If your api key is valid it will automatically load available chat models such as GPT-3, GPT-4, etc. You can choose a model of your choice and start chatting with your assistant. You can also customize instructions for your specific task and fine tune advanced settings for your needs.
- Model: The model which will generate the completion. Some models are suitable for natural language tasks, others specialize in code.
- Temparature: Controls randomness. Lowering results in less random completions. As the temperature approaches zero, the model will become deterministic and repetitive.
- Maximum Tokens (Length): The maximum number of tokens to generate shared between prompt and completion. The exact limit varies by model. One token is roughly 4 characters for standart English text.
- Stop sequences: Up to four sequences where the API will stop generating further tokens. The returned text will not containt the stop sequence.
- Top P: Controls diversity via nucleus sampling. 0.5 means half of all likelihood-weighted options are considered.
- Frequency penalty: How much to penalize new tokens based on their existing frequency in the text so far. Decreases the model's likelihood to repeat the same line verbatim.
- Presence penalty: How much to penalize new tokens based on whether they appear in the text so far. Increases the model's likelihood to talk about new topics. Each assistant card can be deleted or duplicated from top left dropdown menu buttons.
Custom API Calls
When you select an assistant card, it will automatically start an API server on the API URL and port specified in the assistant settings. You can use this URL to make custom API calls to the assistant. Please see the Llama.cpp API documentation for more information.
License
KodiBot Copyright © 2024
KodiBot is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
KodiBot is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with KodiBot. If not, see https://www.gnu.org/licenses.